
Glueジョブの概要と基本的な使い方について解説します。
Glueジョブとは
Glueジョブの概要
Glueジョブは、Lambdaと同じようにサーバーレスでPythonプログラムなどを実行できる仕組みです。
S3と連携し、データ抽出・変換・ロード(Extract・Transform・Load:ETL)に主に使われます。例えば、S3をデータレイクやデータウェアハウスと位置付け、Glueジョブを使ってS3(データレイク・データウェアハウス)からデータを抽出し、特定のデータにのみに変換してデータマート化し、S3にロードし直すようなケースです。
内部的にはApache Spark環境上で実行されるため、ビッグデータ処理に適しています。
Lambdaとの違い
Lambdaとの違いを下表にまとめます。
| 項目 | Lambda | Glueジョブ |
|---|---|---|
| 実行方法 | ・手動実行 ・EventBridge ・API Gateway などから起動できる | ・手動実行 ・Lambda ・Glueワークフロー などから起動できる (EventBridgeやAPI Gatewayからは起動できない) |
| 実行時間 | 15分以内 | 規定されていない(デフォルトは2,880分) |
| メモリ | 10GB以内 (ページングしないため、超えた瞬間にエラー) | 32GB以内 (ページングしないため、超えた瞬間にエラー) |
| ディスク | 512MB以内 | 128GB以内 |
Glueジョブの作成方法
Glueジョブの作成方法について解説します。
IAMロールの用意
Glueジョブが実行できように、IAMロールを用意します。
基本的なIAMロールの追加方法は、こちらの「IAMポリシーの追加」「IAMロールの追加」を参考にして下さい。
IAMポリシーは以下のように設定します。
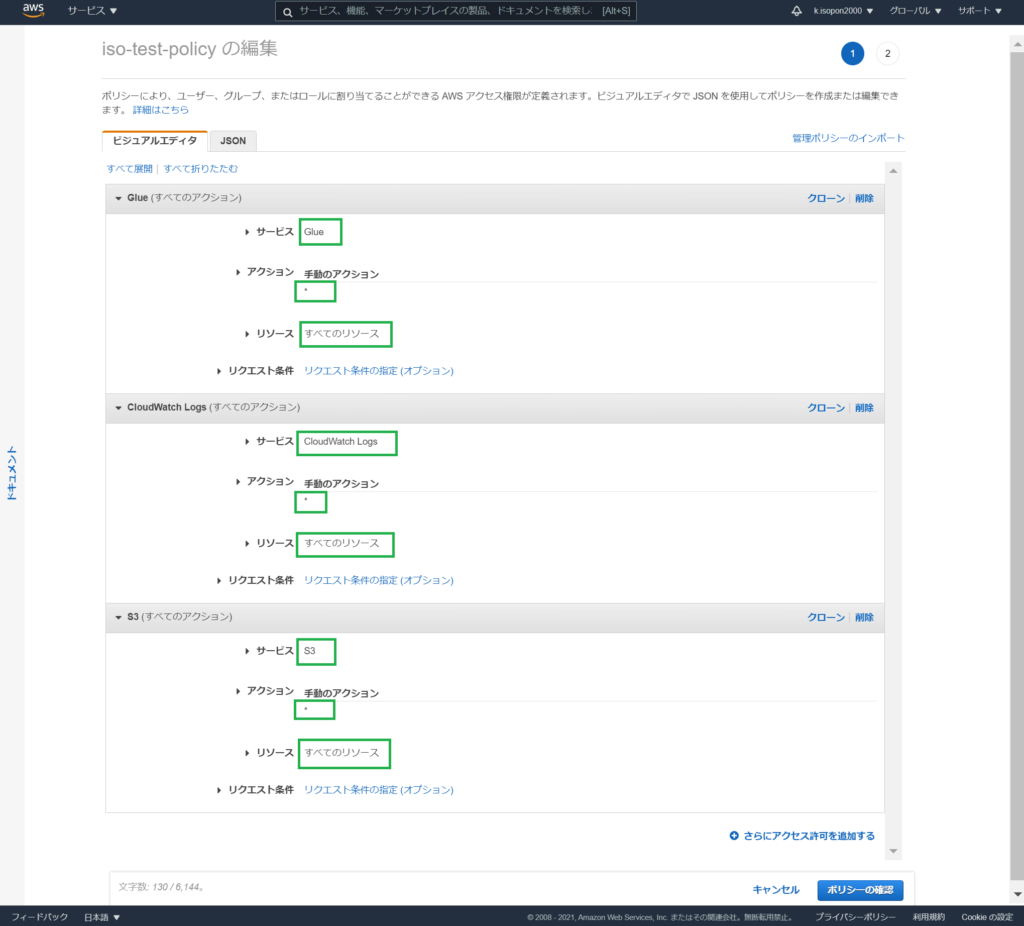
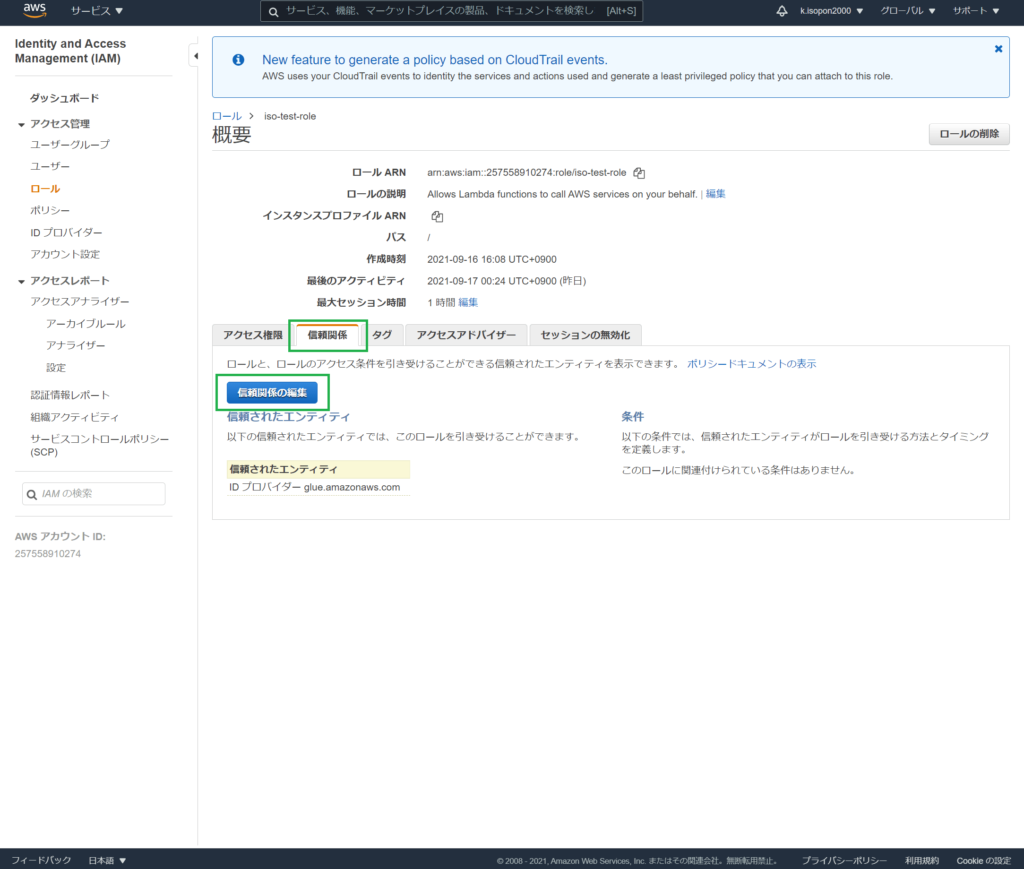
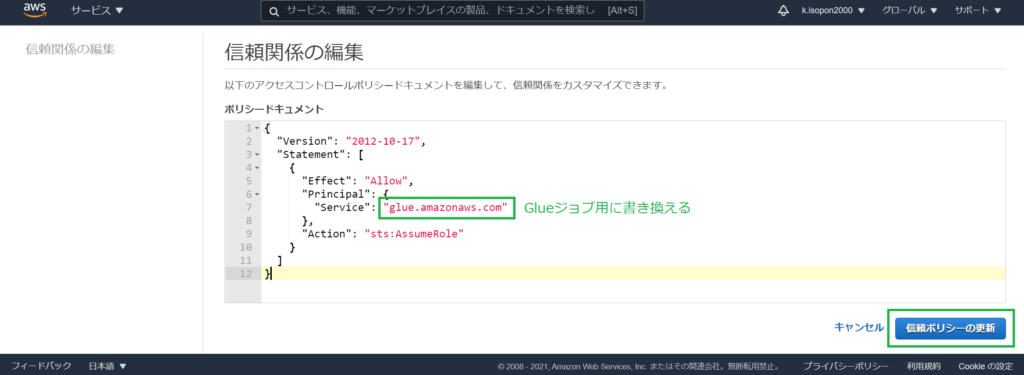
IAMロールの信頼関係を、以下のように設定します。
Glueジョブの追加
Glueジョブを追加します。
AWSマネージメントコンソール > サービス > Glue > ジョブで、(Glue)ジョブの追加をします。
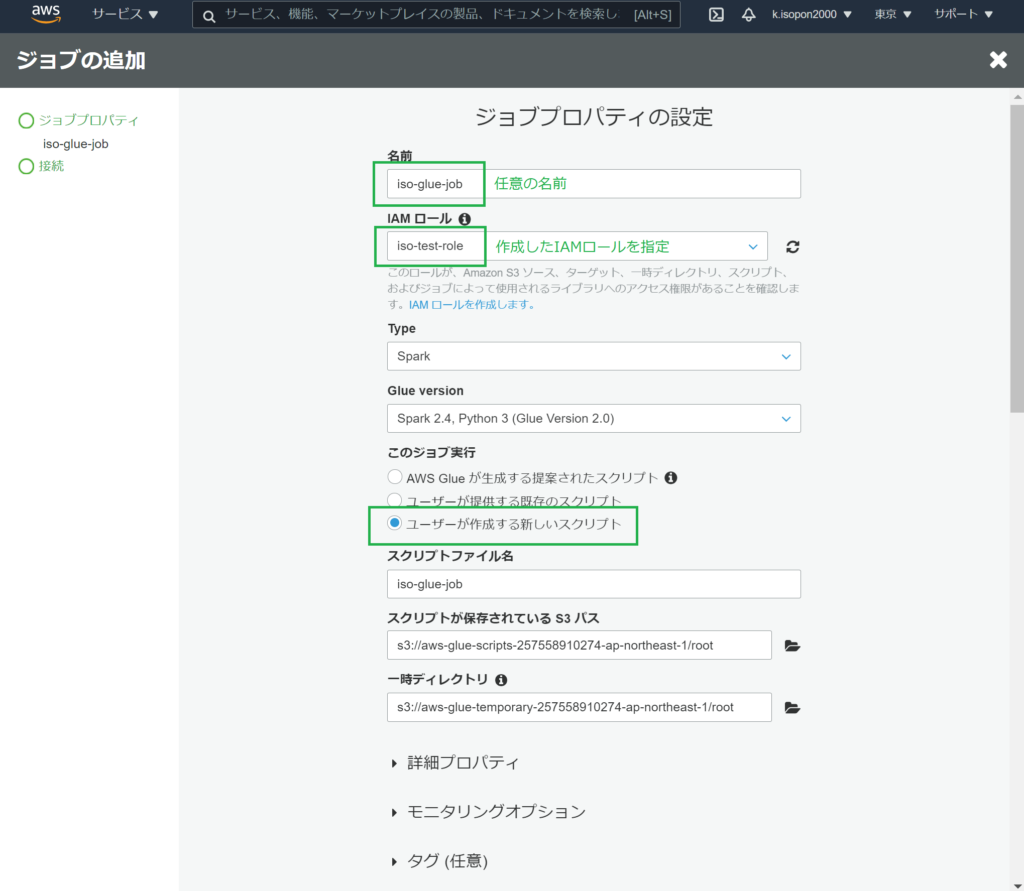
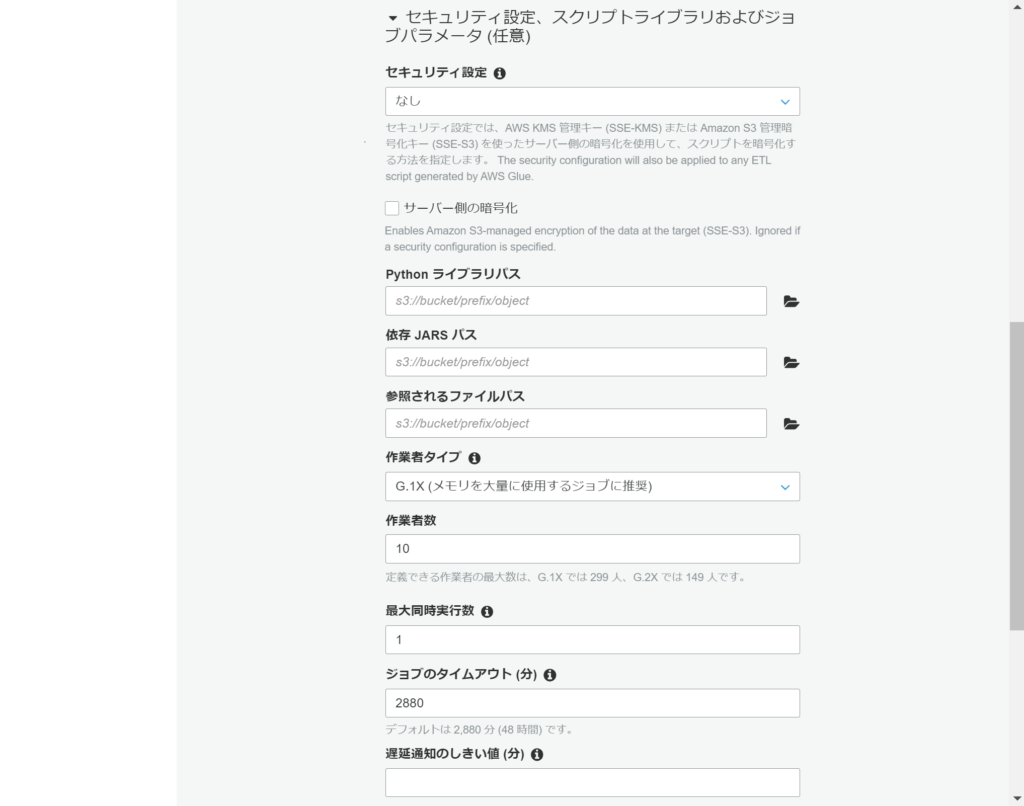
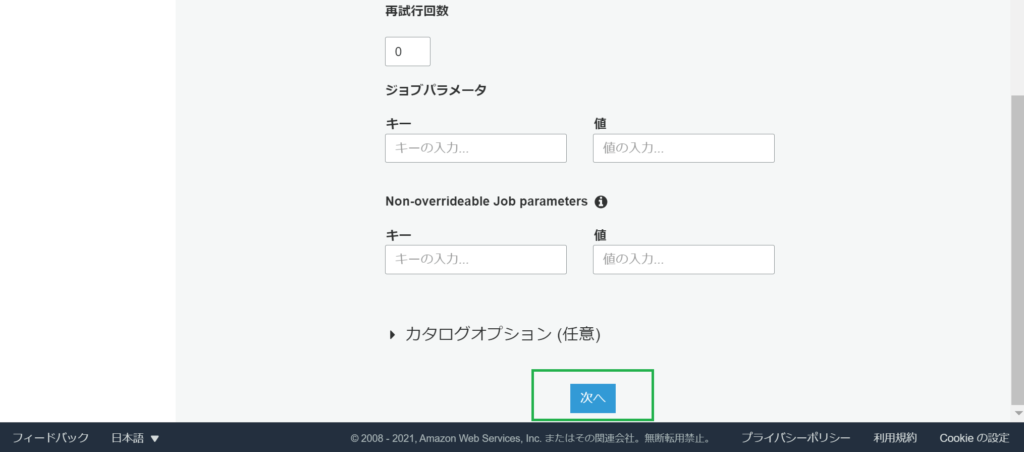
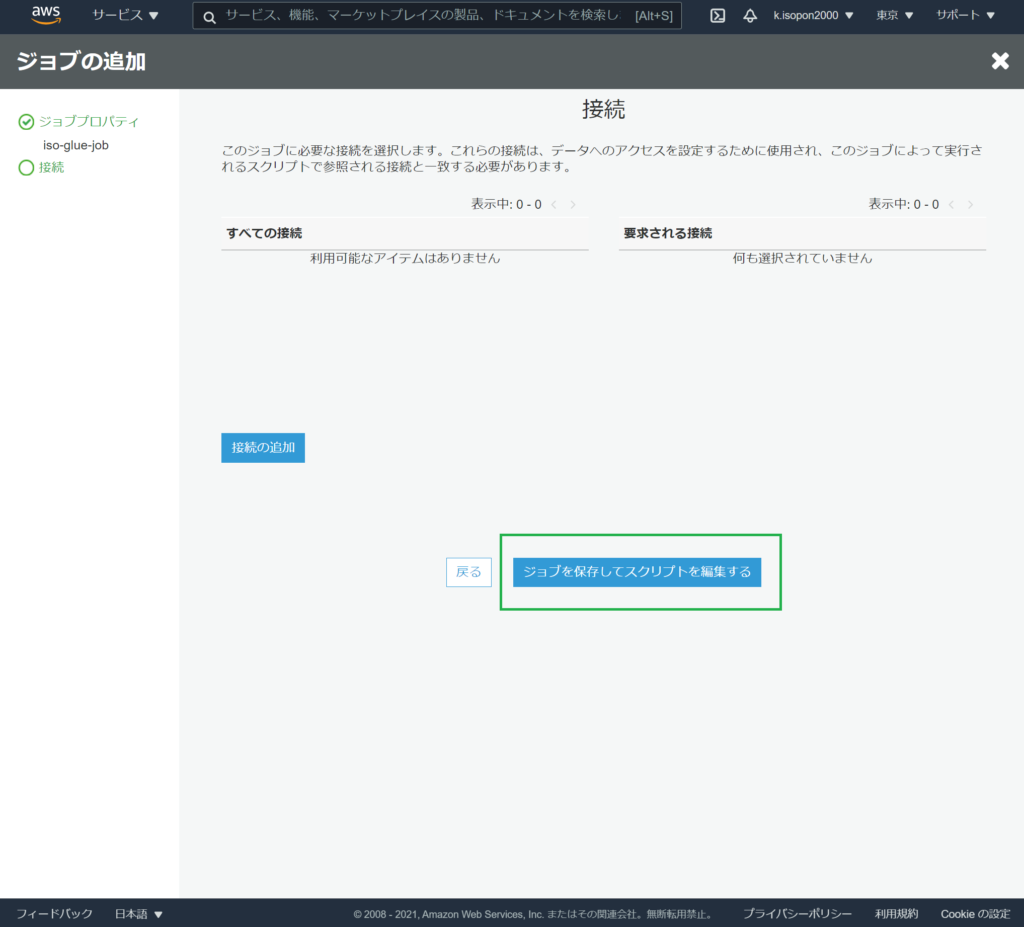
任意の実装を行い、ジョブを実行します。
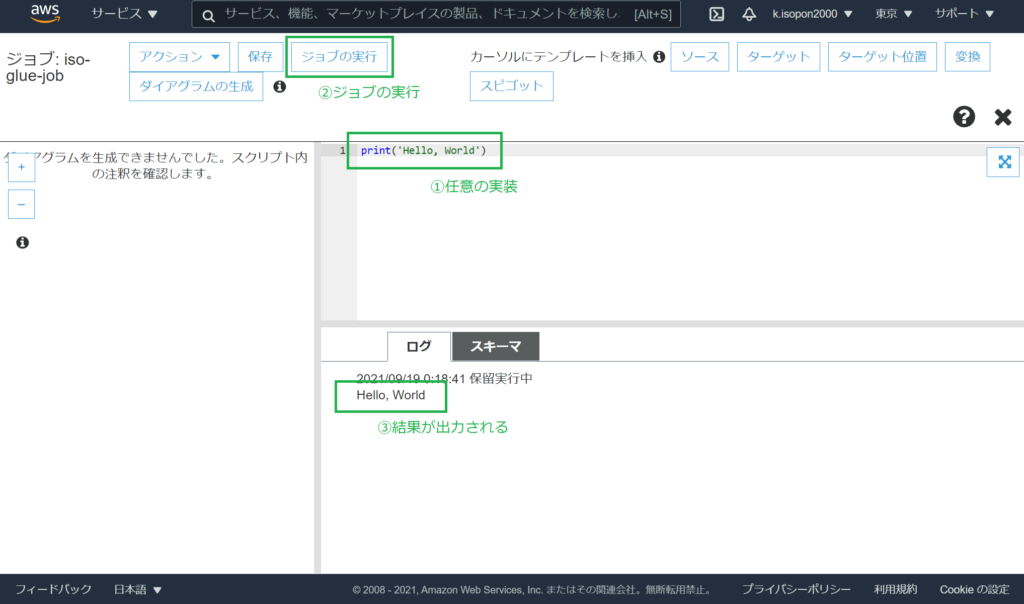
以上で、Glueジョブを追加することができました。
参考:外部ライブラリの呼び出し
Glueジョブから外部に存在するライブラリを呼び出す方法を解説します。
ローカル環境に「C:\lambda\lib」のようなフォルダを作成します。
さらに、「C:\lambda\lib\test.py」のようなPythonファイルを作成します。Glueジョブからはこのtest.pyを呼び出すものとします。
test.pyを以下のように実装します。
def hello_world():
print('Hello, World')「C:\lambda\lib」フォルダをZIP化します。
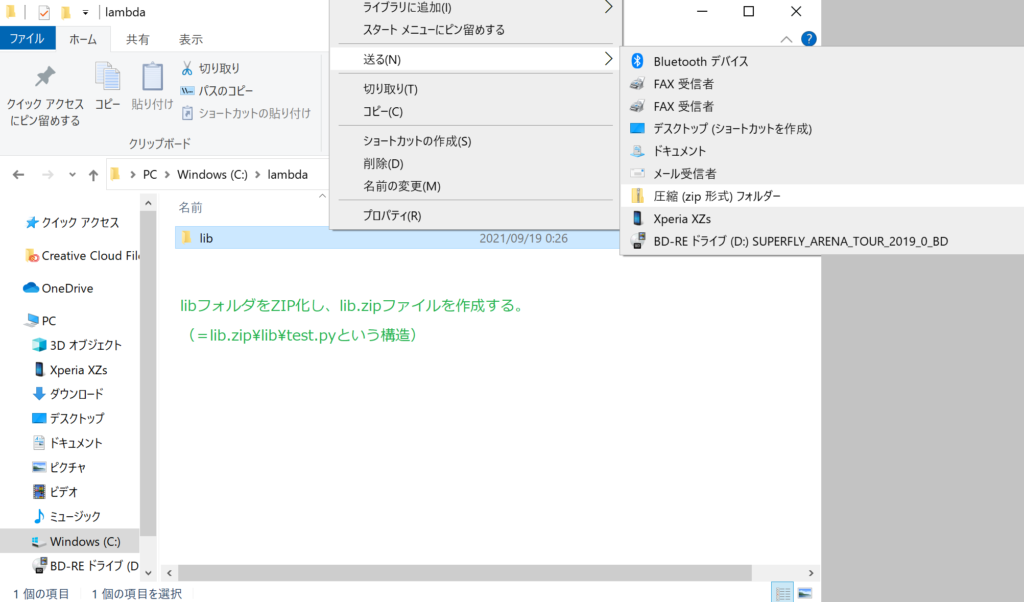
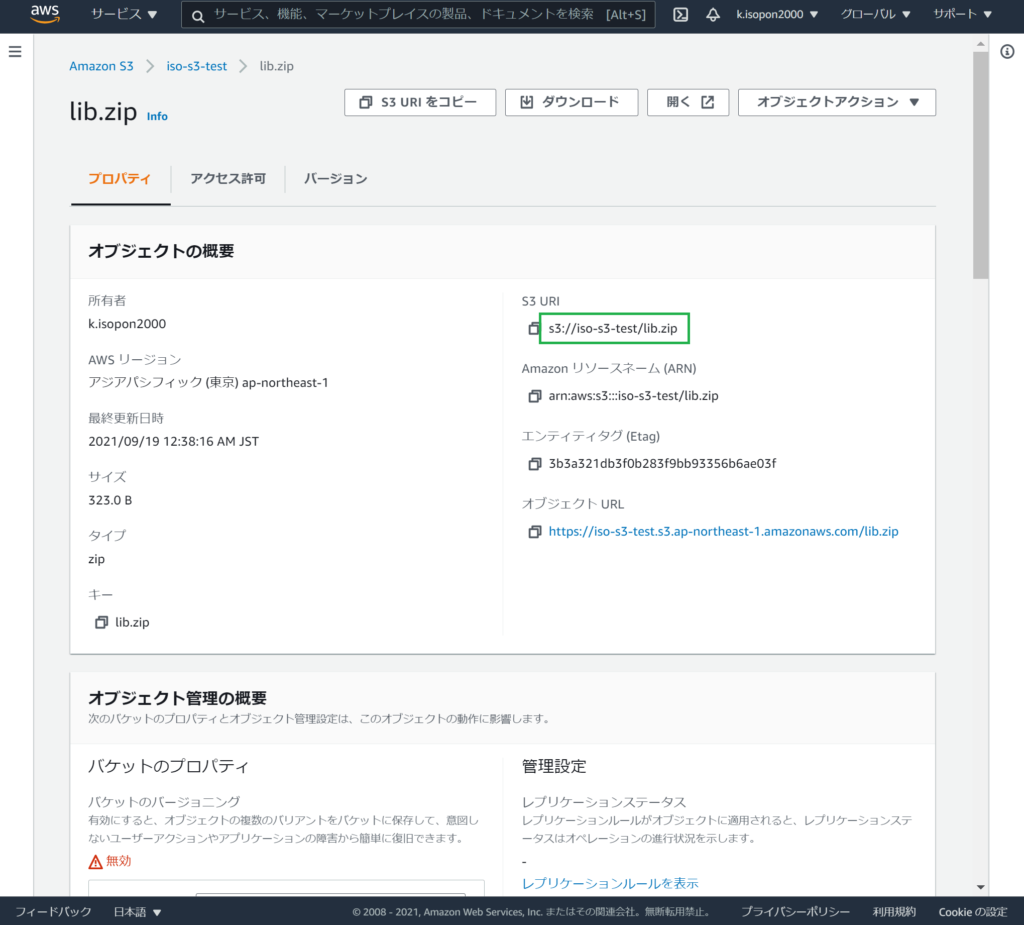
同ZIPファイルをS3にアップロードし、S3 URIを控えます。
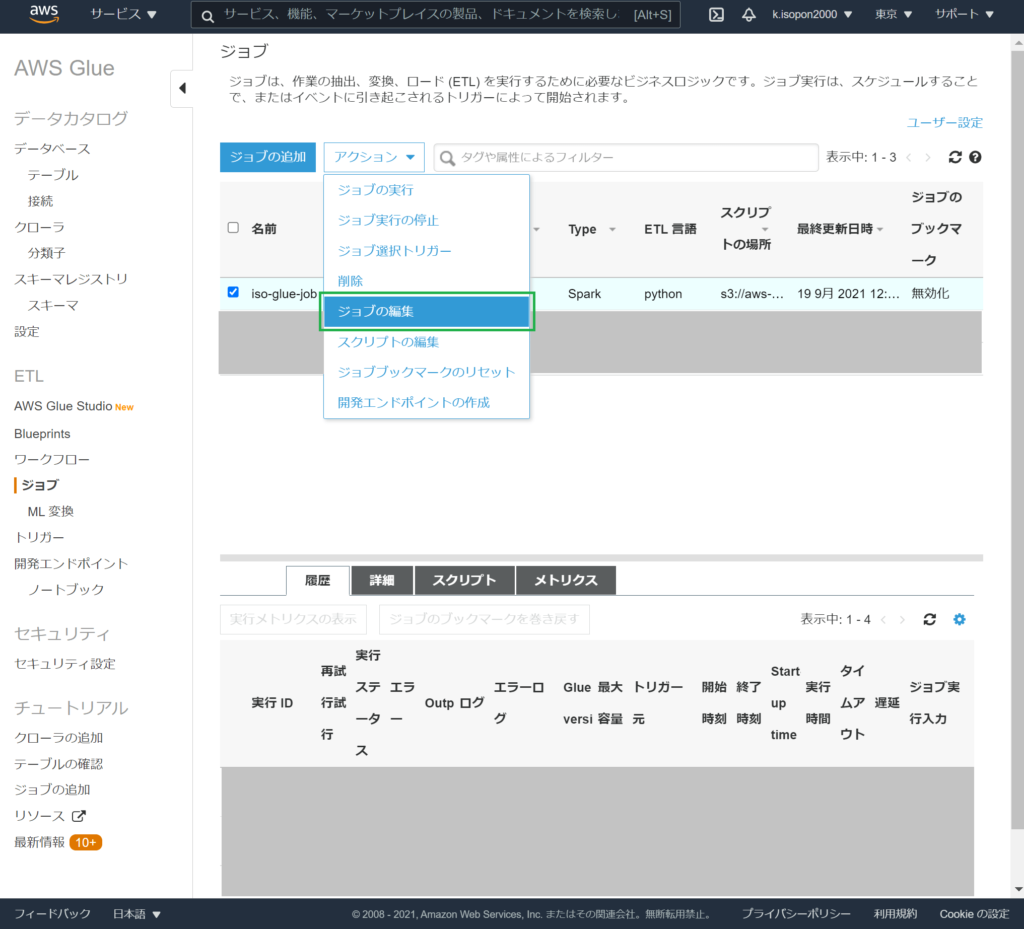
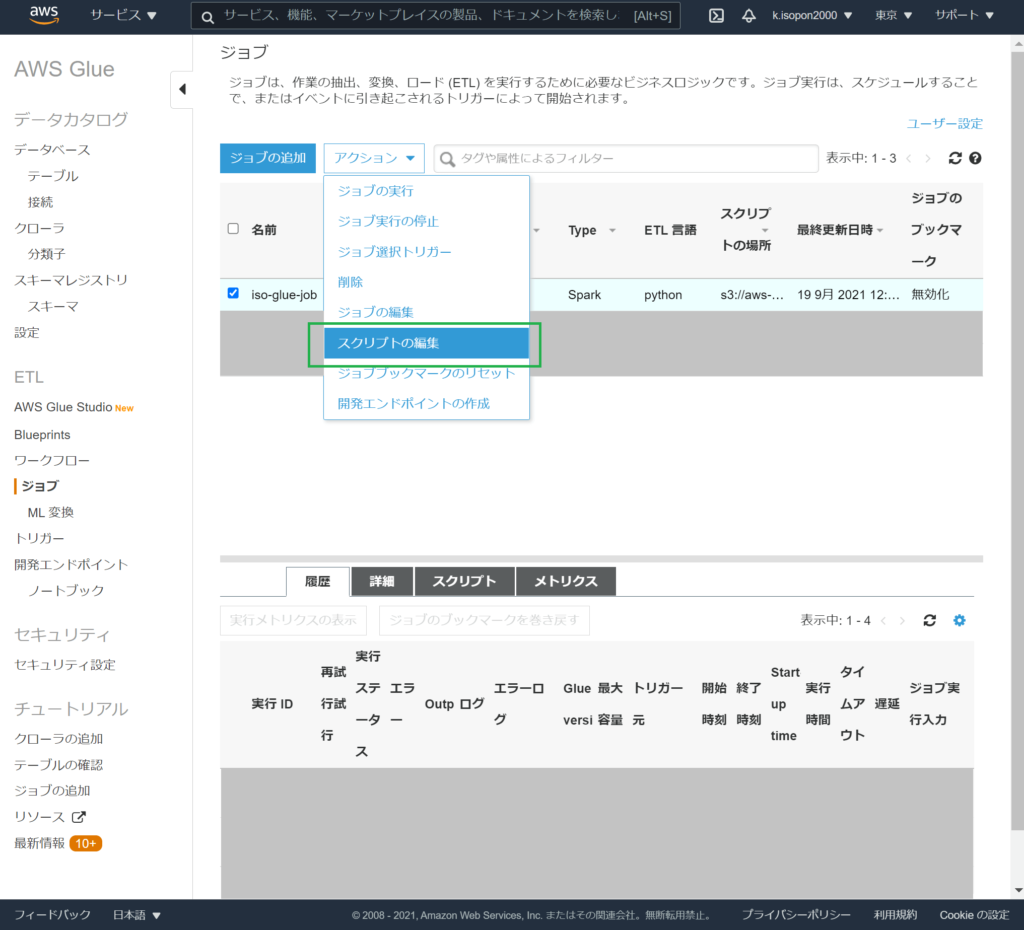
AWSマネージメントコンソール > サービス > Glue > ジョブで、ジョブの編集を行います。
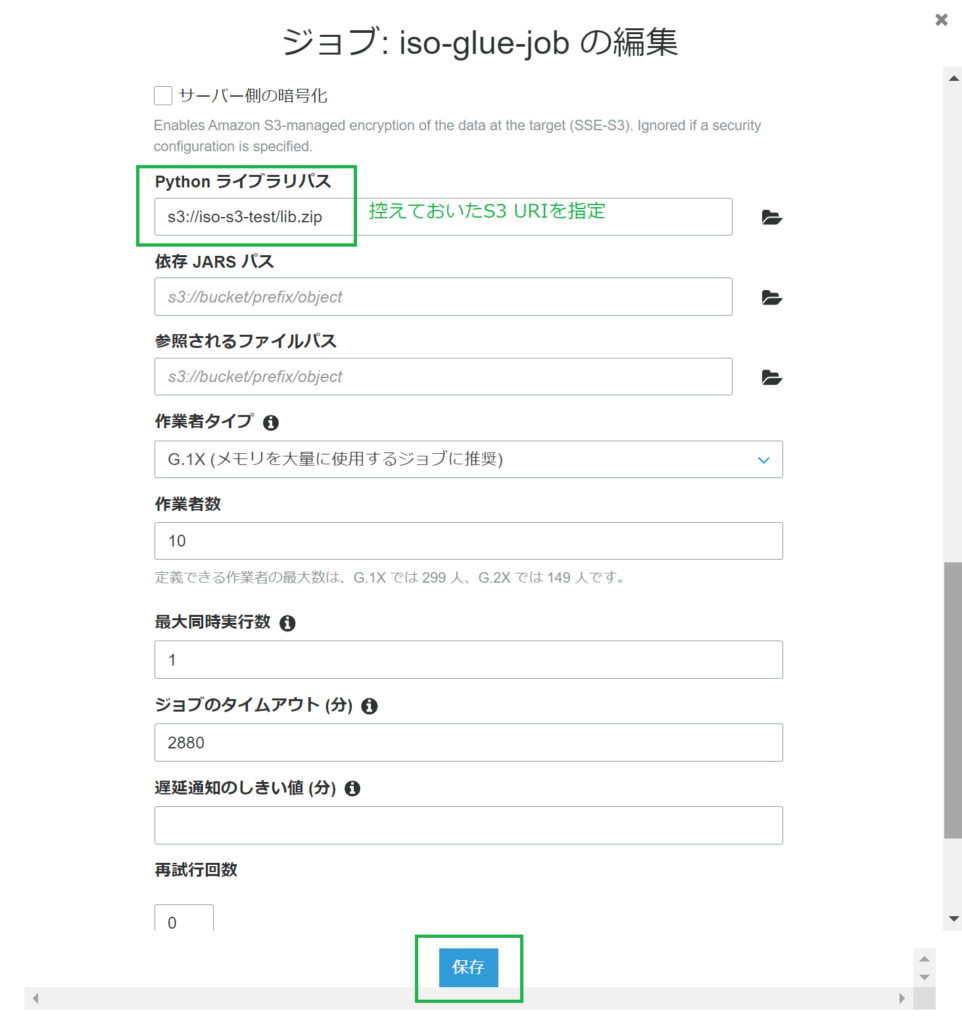
GlueジョブのPythonスクリプトを書き換えます。
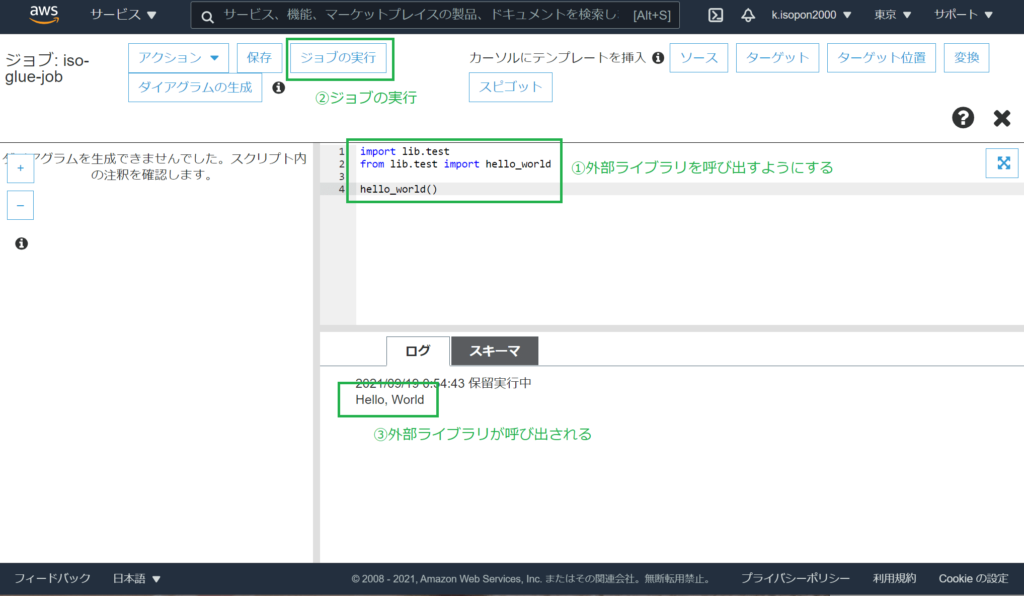
import lib.test
from lib.test import hello_world
hello_world()これでGlueジョブから外部に存在するライブラリを呼び出すことができました。

